3.1 Team Data Science Process
El Team Data Science Process (TDSP) es una metodología ágil e iterativa para ejecutar y entregar soluciones de Analística Avanzada y Machine Learning, diseñanda por Microsoft. Está diseñada para mejorar la colaboración y la eficiencia de los equipos de científico de datos en las organizaciones.
El TDSP consta de 4 componentes:
- Una definición estándar de ciclo de vida de un proyecto de ciencia de datos En particular, extiende la definición CRISP-DM.
- Una estructura de proyecto estandarizada que define como debe ser la organización del código y de los documentos del proyecto.
- Recomendaciones para la gestión ágil de la infraestructura y los recursos utilizados en un proyecto de ciencia de datos.
- Herramientas para un arranque rápido y automatización de tareas de un proyecto de ciencia de datos, incluyendo control de versiones de código, planificación del trabajo, explotación de datos, etc.
El ciclo de vida que utiliza el TDSP considera que las principales etapas, a veces de forma iterativa, de un proyecto de ML son:
- Business understanding
- Data acquisition and understanding
- Modelling
- Deployment
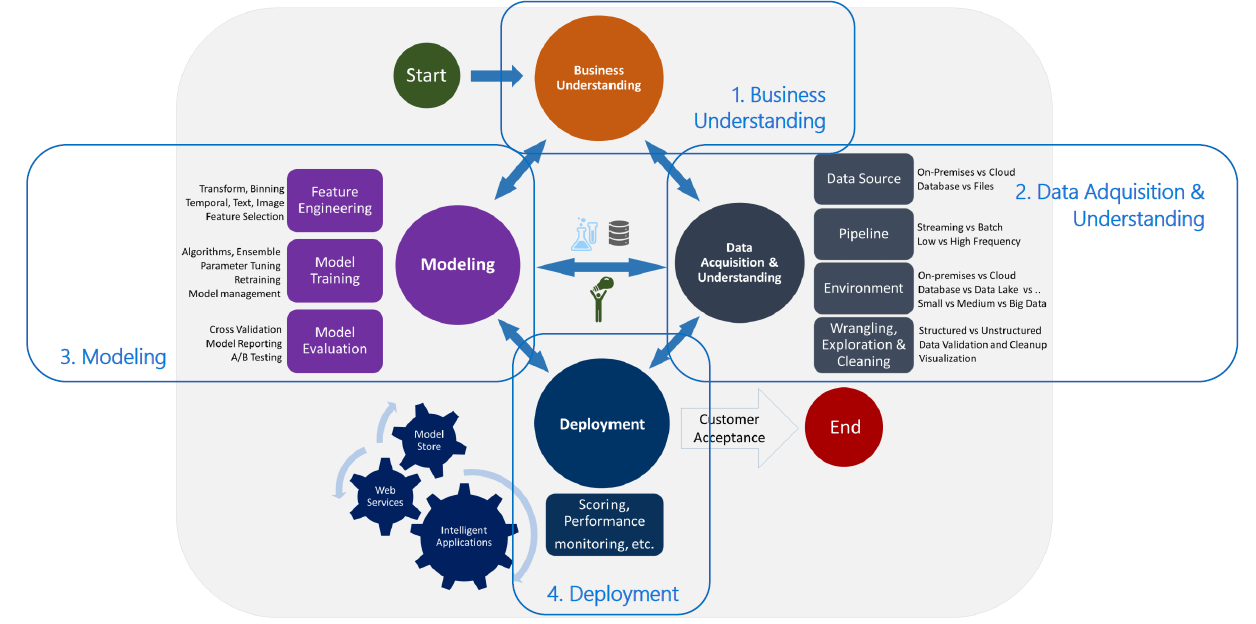
3.1.1 Business Understanding
Los objetivos específicos de esta etapa son:
- Especificar las variables clave para nuestro objetivo de negocio y los critérios (métricas) para medir la satisfacción con el resultado del proyecto
- Identificar las fuentes (orígenes) de datos relevantes para el proyecto, tanto internas como externas (y que es necesario obtener)
- Localización de los indicadores relevantes que van a ayudar a responder a las preguntas que definen los objetivos del negocio.
Los entregables (artifacts) de esta etapa son:
- Documentos marco
- Origenes de datos
- Diccionarios de datos
3.1.2 Data Acquisition & Understanding
Los objetivos específicos de esta etapa son:
- Crear el conjunto de datos (limpio y de alta calidad) cuya relación con las variables respuesta se entienda. Colocar el conjunto de datos en el entorno de desarrollo adecuado.
- Desarrollar una arquitectura de solución para el flujo de trabajo (pipeline), que actualice los datos y obtenga las previsiones con regularidad.
Algunos de los temas que deben ser abordados en esta etapa son:
Volumen de datos. Los requerimientos básicos para los modelos predictivos son: (a) Un conjunto grande de ejemplos históricos para el escenario en cuyo contexto se realizarán las predicciones, y (b) Cada ejemplo histórico debe tener datos suficientes para describir el escenario y el resultado que se va a predecir.
Ventana temporal. Los periodos que deben definirse al definir un modelo predictivo son: (a) Periodo de observación:el periodo que describe las características que se usan para prever la respuesta, y (b) Periodo de consecuencia: el momento del tiempo sobre el cual se calcula la respuesta. En el caso de los modelos de propensión al churn en telecomunicaciones, por ejemplo, se asigna un score a cada cliente sobre su probabilidad de baja a dos meses vista (es decir, hay dos meses de distancia entre el periodo de observación y el periodo de consecuencia). Este criterio es define con la finalidad de disponer de tiempo para el diseño de acciones de parte de negocio (el resultado del modelo se entrega a los gestores de campañas con dos meses de anticipación al momento en que se estima puede ocurrir la baja.
Datos faltantes (missing values). Entre las causas de problemas con los datos están: (a) errores en los procesos de carga e integración, (b) errores en la lógica de construcción de variables derivadas, (c) errores procedentes de la alta o edición manual de los datos; y (d) el hecho que los datos se recogen en las fuentes originales a determinadas fechas/horas. Determinar la causa de los datos faltantes (missing values) ayuda a decidir si se debe intervenir para corregir el problema o no. Este análisis se refleja en un Informe de Calidad de Datos.
Algunas de las alternativas para completas los datos faltantes son:
Excluir la variable del análisis. Un criterio puede ser ‘’la proporción de valores que faltan entre todas las instancias es mayor al 60%’’. Por ejemplo, en un modelo de fuga se considera que el ingreso neto del cliente es una variable fundamental. Si sólo se dispone de ese dato para el 25% de los clientes, y no hay manera de aumentar ese porcentaje, se puede optar por excluir esa variable del estudio.
Crear una variable dicotómica (flag) que indique que se trata de un valor perdido o faltante. Algunas veces la falta de valoes en una variable puede estar relacionada con la respuesta a predecir.
Eliminar los casos (individuos de la muestra) donde falten datos. Esta opción es peligrosa porque se puede crear sesgo en los datos. Para evitar este problema se recomienda después de analizar la posible relación entre los casos a eliminar del estudio y la respuesta que se va a estimar.
Reemplazar los valores que falten con otros estimados a partir de datos conocidos. Habitualmente se procede a imputar datos faltantes con medidas de tendencia central (media o mediana para las variables contínuas y moda para las variables categóricas)
Datos atípicos (outliers). Los valores atípicos pueden ser de dos tipos: (a) Válidos, cuando su presencia tiene un motivo conocido y, (2) Inválidos, conocidos también como ruido, son valores que han sido registrados como consecuencia de un error.
Para identificar outliers se suele: (a) examinar el rango de valores observado históricamente, considerado válido y (b) comparar la distancia entre diferentes percentiles de la muestra.
- Visualización. Existen muchas opciones para representar los datos disponibles. Utilizar el gráfico adecuado al tipo de datos es muy importante para evitar conclusiones engañosas.
Los entregables (artifacts) de esta etapa son:
- Informe de calidad de los datos
- Arquitectura de la solución
- Decisión de punto de control
3.1.3 Modelling
Los objetivos de esta fase son:
- Determinar las mejore variables/datos para el modelo.
- Crear un modelo de ML que realiza la previsión de la variable obketivo (respuesta) con la máxima precisión.
- Crear un modelo de ML que es adecuado para entornos de producción.
Específicamente, algunas de las tareas que deben llevarse a cabo son:
Selección de variables. Consiste en incluir, agregar y transformar datos sin procesar para crear las variables que se utilizan en el análisis. Este paso requiere de una combinación de experiencia con el negocio y los conocimientos obtenidos en el paso de exploración de datos. El objetivo es buscar e incluir variables informativas, evitando al mismo tiempo que se utilicen demasiadas variables. De esta forma se mejoran los resultados y se minimiza el ruido que pueden causar las variables no relacionadas con la variable respuesta.
Selección del modelo. Consiste en determinar el modelo que responda a la pregunta de negocio con la máxima precisión posible. Para ello se ejecutan, de manera iterativa, las siguientes tareas: (a) dividir los datos en el conjunto de aprendizake y conjunto de prueba, (b) compilar los modelos, (c) evaluar el modelo ajustado/entrenado y (d) comparar las métricas obtenidas de la diagnosis de los resultados para selección el mejor modelo.
Los entregables (artifacts) de esta etapa son:
- Conjunto de variables para el modelo (datamart analítico)
- Informe técnico del modelo
- Decisión de punto de control
3.1.4 Deployment
El objetivo de esta fase es implementar el modelo y el flujo de trabajo (pipeline) en un entorno de producción para que el usuario final lo acepte.
Cuando se ha decidido poner en producción un modelo, se debe pasar a la etapa de operacionalización para que otras aplicaciones lo consuman. Uno de los aspectos que se debe tener en cuenta es si el consumo será en real time o batch. Generalmente se crea un API que permite que el modelo sea utilizado por otras aplicaciones:
- Sitios web en línea
- Hojas de cálculo
- Paneles de control (dashboards)
- Aplicaciones de línea de negocio
- Aplicaciones de back-end
Los entregables (artifacts) de esta etapa son:
- Un dashboard de estado que muestra el estado del sistema y métricas clave.
- Un informe del modelo final y detalles de implementación.
- Un documento de arquitectura de la solución final.
3.1.5 Customer Acceptance
Aunque pocas veces se visualiza como parte del proceso de ciencia de datos, la aceptación del Cliente es necesaria para la finalización del proyecto. Se debe que confirmar el flujo de trabajo (pipeline), el modelo y su implementación en un entorno de producción cumplen los objetivos del Cliente.
El entregable (artifact) de esta etapa es el Informe de salida del proyecto.
El TDSP puede ser utilizado fácilmente en Azure Machine Learning debido a que la plantillas de estructura del proyecto y documentación se pueden instanciar en pocos pasos1